GPT5不知道怎么用?OpenAI手把手教你最大化压榨推理模型!
OpenAI官方推理模型最佳实践
推理最佳实践
了解何时使用推理模型及其与GPT模型的差异。
OpenAI提供两类模型:推理模型(例如o3和o4-mini)和GPT模型(如GPT-4.1)。这两类模型具有不同特性。
本指南涵盖:
- 推理模型与非推理GPT模型的区别
- 推理模型适用场景
- 高效的推理模型提示方法
更多关于推理模型工作原理的内容。
推理模型 vs GPT模型
相比GPT模型,o系列模型擅长不同任务且需要不同的提示方式。二者并无优劣之分,只是定位不同。
我们训练o系列模型("规划者")进行更长时间的复杂任务思考,使其擅长战略制定、复杂问题解决方案规划和基于大量模糊信息的决策。这些模型还能高精度执行任务,是数学、科学、工程、金融和法律等专业领域的理想选择。
而低延迟、高性价比的GPT模型("执行者")专为直接执行设计。一个应用可能使用o系列模型制定问题解决策略,再用GPT模型执行具体任务——特别是当速度和成本比绝对精度更重要时。
选择标准
您的需求优先级是?
- 速度和成本 → GPT模型更快更经济
- 明确任务执行 → GPT模型擅长定义清晰的任务
- 准确性和可靠性 → o系列模型是可靠的决策者
- 复杂问题解决 → o系列模型能处理模糊复杂问题
如果任务完成的速度和成本最关键,且您的用例是简单明确的任务,GPT模型最适合。但如果准确性和可靠性最关键,且您需要解决复杂的多步骤问题,o系列模型更合适。
多数AI工作流会组合使用两类模型——o系列负责自主规划和决策,GPT系列负责任务执行。
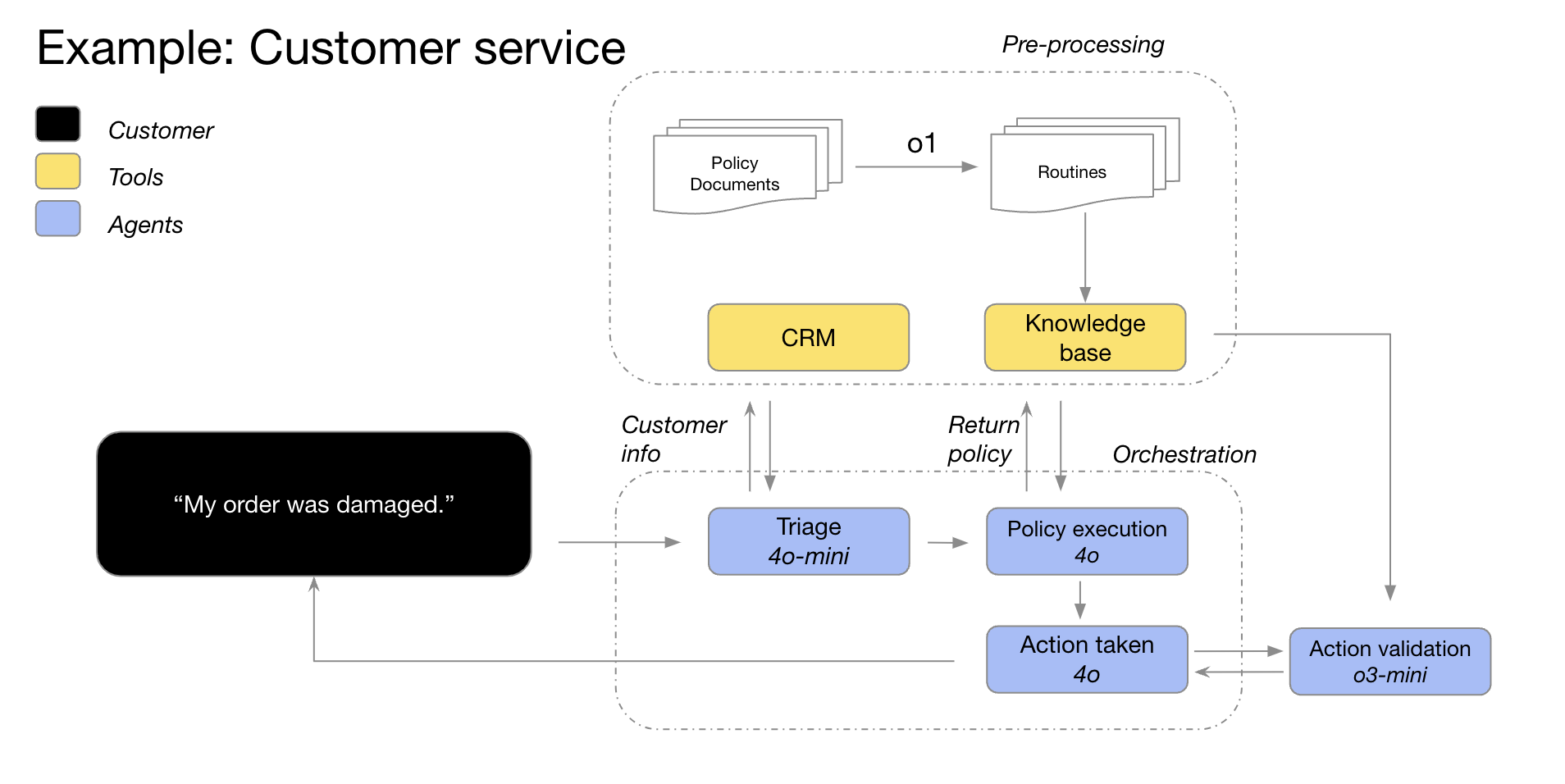
GPT-4o和GPT-4o mini模型处理订单详情与客户信息,识别订单问题和退货政策,然后将这些数据输入o3-mini做出最终退货决策。
推理模型适用场景
以下是我们从客户和OpenAI内部观察到的成功用例模式,提供实用的o系列模型测试指导。
1. 处理模糊任务
推理模型特别擅长通过简单提示理解用户意图,处理信息缺失的模糊任务。它们通常会先提出澄清问题,而非盲目猜测。
"o1的推理能力使我们的多智能体平台Matrix能生成详尽、格式规范的回答。例如,o1仅用基础提示就能识别信贷协议中的受限支付额度。在复杂信贷协议提示测试中,o1在52%的情况下优于其他模型。"
—Hebbia,法律金融AI知识平台
2. 大海捞针
当处理大量非结构化信息时,推理模型能精准提取关键信息。
"分析公司收购案时,o1审查了数十份文件,发现脚注中的'控制权变更'条款:公司被收购需立即偿还7500万美元贷款。这种极致细节把控使我们的AI能辅助金融专业人士识别关键信息。"
—Endex,金融智能AI平台
3. 大数据集关联分析
推理模型擅长处理数百页密集非结构化文件(如法律合同、财务报表、保险索赔),能发现文档间关联并基于数据隐含逻辑决策。
"税务研究需要综合多份文件。改用o1后,我们发现其推理能力带来端到端性能4倍提升——它能发现单份文档中不明显的逻辑关联。"
—Blue J,税务研究AI平台
4. 多步骤自主规划
推理模型是自主规划和策略制定的核心。典型案例是用作"规划者"生成详细解决方案,再根据任务需求分配GPT模型执行。
"o1作为规划者协调其他模型完成多步骤任务,擅长数据分类和问题拆解。"
—Argon AI,医药行业AI知识平台
5. 视觉推理
目前o1是唯一支持视觉的推理模型,能解析复杂图表、模糊结构表格和低质量图片。
"在风险合规审查中,GPT-4o对最难图像分类任务准确率50%,而o1达到88%且无需修改流程。"
—SafetyKit,风险合规AI平台
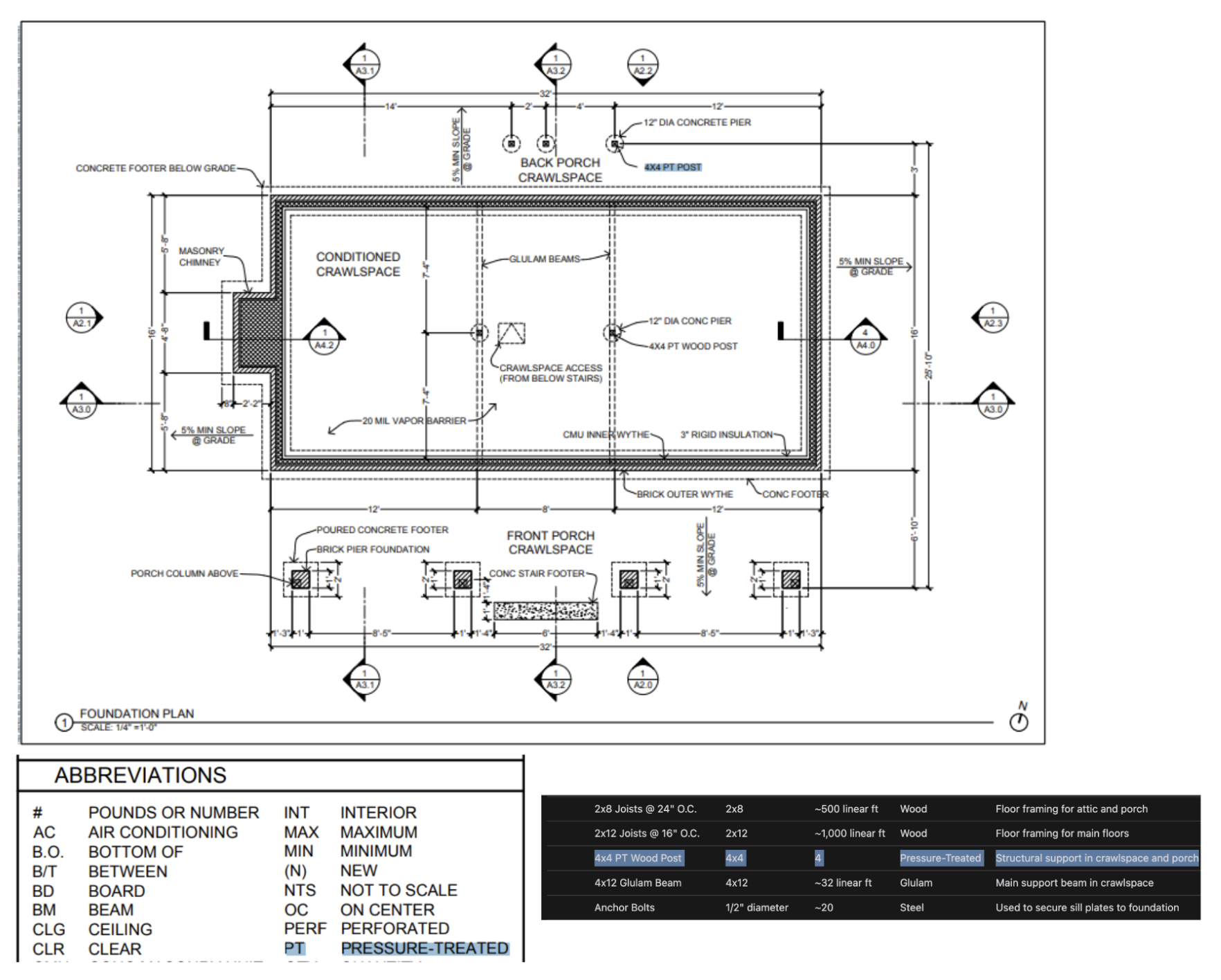
内部测试显示,o1能识别建筑图纸细节生成材料清单,并能跨页面正确应用图例说明。
6. 代码审查与优化
推理模型特别适合审查和改进大量代码,常作为后台代码审查工具。
"我们为GitHub等平台提供AI代码审查服务。o1能可靠检测代码库中可能被人忽略的细微改动,使产品转化率提升3倍。"
—CodeRabbit,AI代码审查初创公司
7. 模型响应评估
推理模型在评估其他模型响应时表现优异,特别适合医疗等敏感领域的数据验证。
"许多客户用LLM-as-a-judge进行评估。例如医疗公司用GPT-4o总结患者问题,再用o1评估质量。某客户评估F1分数从0.12(4o)提升至0.74(o1)。"
—Braintrust,AI评估平台
高效提示技巧
这些模型最适合简洁直接的提示。某些提示工程技巧(如"逐步思考")可能适得其反。
- 开发者消息替代系统消息:从
o1-2024-12-17开始支持开发者消息 - 保持提示简洁直接
- 避免思维链提示:模型已内置推理能力
- 使用分隔符增强清晰度
- 优先零样本提示
- 明确约束条件和目标
- 标记格式化需求:开发者消息首行添加
Formatting re-enabled启用Markdown
成本控制与精度保障
使用o3和o4-mini时,响应API中的持久化推理项会区别处理。建议:
- 启用响应API的
store参数 - 传入历史推理项
- 对于涉及多个函数调用的复杂场景,至少包含最近函数调用与用户消息间的推理项
其他资源
英文原文
Reasoning best practices
Learn when to use reasoning models and how they compare to GPT models.
OpenAI offers two types of models: reasoning models (o3 and o4-mini, for example) and GPT models (like GPT-4.1). These model families behave differently.
This guide covers:
- The difference between our reasoning and non-reasoning GPT models
- When to use our reasoning models
- How to prompt reasoning models effectively
Read more about reasoning models and how they work.
Reasoning models vs. GPT models
Compared to GPT models, our o-series models excel at different tasks and require different prompts. One model family isn't better than the other—they're just different.
We trained our o-series models (“the planners”) to think longer and harder about complex tasks, making them effective at strategizing, planning solutions to complex problems, and making decisions based on large volumes of ambiguous information. These models can also execute tasks with high accuracy and precision, making them ideal for domains that would otherwise require a human expert—like math, science, engineering, financial services, and legal services.
On the other hand, our lower-latency, more cost-efficient GPT models (“the workhorses”) are designed for straightforward execution. An application might use o-series models to plan out the strategy to solve a problem, and use GPT models to execute specific tasks, particularly when speed and cost are more important than perfect accuracy.
How to choose
What's most important for your use case?
- Speed and cost → GPT models are faster and tend to cost less
- Executing well defined tasks → GPT models handle explicitly defined tasks well
- Accuracy and reliability → o-series models are reliable decision makers
- Complex problem-solving → o-series models work through ambiguity and complexity
If speed and cost are the most important factors when completing your tasks and your use case is made up of straightforward, well defined tasks, then our GPT models are the best fit for you. However, if accuracy and reliability are the most important factors and you have a very complex, multistep problem to solve, our o-series models are likely right for you.
Most AI workflows will use a combination of both models—o-series for agentic planning and decision-making, GPT series for task execution.
Our GPT-4o and GPT-4o mini models triage order details with customer information, identify the order issues and the return policy, and then feed all of these data points into o3-mini to make the final decision about the viability of the return based on policy.
When to use our reasoning models
Here are a few patterns of successful usage that we’ve observed from customers and internally at OpenAI. This isn't a comprehensive review of all possible use cases but, rather, some practical guidance for testing our o-series models.
Ready to use a reasoning model? Skip to the quickstart →
1. Navigating ambiguous tasks
Reasoning models are particularly good at taking limited information or disparate pieces of information and with a simple prompt, understanding the user’s intent and handling any gaps in the instructions. In fact, reasoning models will often ask clarifying questions before making uneducated guesses or attempting to fill information gaps.
“o1’s reasoning capabilities enable our multi-agent platform Matrix to produce exhaustive, well-formatted, and detailed responses when processing complex documents. For example, o1 enabled Matrix to easily identify baskets available under the restricted payments capacity in a credit agreement, with a basic prompt. No former models are as performant. o1 yielded stronger results on 52% of complex prompts on dense Credit Agreements compared to other models.”
—Hebbia, AI knowledge platform company for legal and finance
2. Finding a needle in a haystack
When you’re passing large amounts of unstructured information, reasoning models are great at understanding and pulling out only the most relevant information to answer a question.
"To analyze a company's acquisition, o1 reviewed dozens of company documents—like contracts and leases—to find any tricky conditions that might affect the deal. The model was tasked with flagging key terms and in doing so, identified a crucial "change of control" provision in the footnotes: if the company was sold, it would have to pay off a $75 million loan immediately. o1's extreme attention to detail enables our AI agents to support finance professionals by identifying mission-critical information."
—Endex, AI financial intelligence platform
3. Finding relationships and nuance across a large dataset
We’ve found that reasoning models are particularly good at reasoning over complex documents that have hundreds of pages of dense, unstructured information—things like legal contracts, financial statements, and insurance claims. The models are particularly strong at drawing parallels between documents and making decisions based on unspoken truths represented in the data.
“Tax research requires synthesizing multiple documents to produce a final, cogent answer. We swapped GPT-4o for o1 and found that o1 was much better at reasoning over the interplay between documents to reach logical conclusions that were not evident in any one single document. As a result, we saw a 4x improvement in end-to-end performance by switching to o1—incredible.”
—Blue J, AI platform for tax research
Reasoning models are also skilled at reasoning over nuanced policies and rules, and applying them to the task at hand in order to reach a reasonable conclusion.
"In financial analyses, analysts often tackle complex scenarios around shareholder equity and need to understand the relevant legal intricacies. We tested about 10 models from different providers with a challenging but common question: how does a fundraise affect existing shareholders, especially when they exercise their anti-dilution privileges? This required reasoning through pre- and post-money valuations and dealing with circular dilution loops—something top financial analysts would spend 20-30 minutes to figure out. We found that o1 and o3-mini can do this flawlessly! The models even produced a clear calculation table showing the impact on a $100k shareholder."
–BlueFlame AI, AI platform for investment management
4. Multistep agentic planning
Reasoning models are critical to agentic planning and strategy development. We’ve seen success when a reasoning model is used as “the planner,” producing a detailed, multistep solution to a problem and then selecting and assigning the right GPT model (“the doer”) for each step, based on whether high intelligence or low latency is most important.
“We use o1 as the planner in our agent infrastructure, letting it orchestrate other models in the workflow to complete a multistep task. We find o1 is really good at selecting data types and breaking down big questions into smaller chunks, enabling other models to focus on execution.”
—Argon AI, AI knowledge platform for the pharmaceutical industry
“o1 powers many of our agentic workflows at Lindy, our AI assistant for work. The model uses function calling to pull information from your calendar or email and then can automatically help you schedule meetings, send emails, and manage other parts of your day-to-day tasks. We switched all of our agentic steps that used to cause issues to o1 and observing our agents becoming basically flawless overnight!”
—Lindy.AI, AI assistant for work
5. Visual reasoning
As of today, o1 is the only reasoning model that supports vision capabilities. What sets it apart from GPT-4o is that o1 can grasp even the most challenging visuals, like charts and tables with ambiguous structure or photos with poor image quality.
“We automate risk and compliance reviews for millions of products online, including luxury jewelry dupes, endangered species, and controlled substances. GPT-4o reached 50% accuracy on our hardest image classification tasks. o1 achieved an impressive 88% accuracy without any modifications to our pipeline.”
—SafetyKit, AI-powered risk and compliance platform
From our own internal testing, we’ve seen that o1 can identify fixtures and materials from highly detailed architectural drawings to generate a comprehensive bill of materials. One of the most surprising things we observed was that o1 can draw parallels across different images by taking a legend on one page of the architectural drawings and correctly applying it across another page without explicit instructions. Below you can see that, for the 4x4 PT wood posts, o1 recognized that "PT" stands for pressure treated based on the legend.
6. Reviewing, debugging, and improving code quality
Reasoning models are particularly effective at reviewing and improving large amounts of code, often running code reviews in the background given the models’ higher latency.
“We deliver automated AI Code Reviews on platforms like GitHub and GitLab. While code review process is not inherently latency-sensitive, it does require understanding the code diffs across multiple files. This is where o1 really shines—it's able to reliably detect minor changes to a codebase that could be missed by a human reviewer. We were able to increase product conversion rates by 3x after switching to o-series models.”
—CodeRabbit, AI code review startup
While GPT-4o and GPT-4o mini may be better designed for writing code with their lower latency, we’ve also seen o3-mini spike on code production for use cases that are slightly less latency-sensitive.
“o3-mini consistently produces high-quality, conclusive code, and very frequently arrives at the correct solution when the problem is well-defined, even for very challenging coding tasks. While other models may only be useful for small-scale, quick code iterations, o3-mini excels at planning and executing complex software design systems.”
—Windsurf, collaborative agentic AI-powered IDE, built by Codeium
7. Evaluation and benchmarking for other model responses
We’ve also seen reasoning models do well in benchmarking and evaluating other model responses. Data validation is important for ensuring dataset quality and reliability, especially in sensitive fields like healthcare. Traditional validation methods use predefined rules and patterns, but advanced models like o1 and o3-mini can understand context and reason about data for a more flexible and intelligent approach to validation.
"Many customers use LLM-as-a-judge as part of their eval process in Braintrust. For example, a healthcare company might summarize patient questions using a workhorse model like gpt-4o, then assess the summary quality with o1. One Braintrust customer saw the F1 score of a judge go from 0.12 with 4o to 0.74 with o1! In these use cases, they’ve found o1’s reasoning to be a game-changer in finding nuanced differences in completions, for the hardest and most complex grading tasks."
—Braintrust, AI evals platform
How to prompt reasoning models effectively
These models perform best with straightforward prompts. Some prompt engineering techniques, like instructing the model to "think step by step," may not enhance performance (and can sometimes hinder it). See best practices below, or get started with prompt examples.
- Developer messages are the new system messages: Starting with
o1-2024-12-17, reasoning models support developer messages rather than system messages, to align with the chain of command behavior described in the model spec. - Keep prompts simple and direct: The models excel at understanding and responding to brief, clear instructions.
- Avoid chain-of-thought prompts: Since these models perform reasoning internally, prompting them to "think step by step" or "explain your reasoning" is unnecessary.
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
- Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
- Provide specific guidelines: If there are ways you explicitly want to constrain the model's response (like "propose a solution with a budget under $500"), explicitly outline those constraints in the prompt.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
- Markdown formatting: Starting with
o1-2024-12-17, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the stringFormatting re-enabledon the first line of your developer message.
How to keep costs low and accuracy high
With the introduction of o3 and o4-mini models, persisted reasoning items in the Responses API are treated differently. Previously (for o1, o3-mini, o1-mini and o1-preview), reasoning items were always ignored in follow‑up API requests, even if they were included in the input items of the requests. With o3 and o4-mini, some reasoning items adjacent to function calls are included in the model’s context to help improve model performance while using the least amount of reasoning tokens.
For the best results with this change, we recommend using the Responses API with the store parameter set to true, and passing in all reasoning items from previous requests (either using previous_response_id, or by taking all the output items from an older request and passing them in as input items for a new one). OpenAI will automatically include any relevant reasoning items in the model's context and ignore any irrelevant ones. In more advanced use‑cases where you’d like to manage what goes into the model's context more precisely, we recommend that you at least include all reasoning items between the latest function call and the previous user message. Doing this will ensure that the model doesn’t have to restart its reasoning when you respond to a function call, resulting in better function‑calling performance and lower overall token usage.
If you’re using the Chat Completions API, reasoning items are never included in the context of the model. This is because Chat Completions is a stateless API. This will result in slightly degraded model performance and greater reasoning token usage in complex agentic cases involving many function calls. In instances where complex multiple function calling is not involved, there should be no degradation in performance regardless of the API being used.
Other resources
For more inspiration, visit the OpenAI Cookbook, which contains example code and links to third-party resources, or learn more about our models and reasoning capabilities:
文章标题:GPT5不知道怎么用?OpenAI手把手教你最大化压榨推理模型!
文章链接:https://www.qimuai.cn/?post=125
本站文章均为原创,未经授权请勿用于任何商业用途